
如何降低规则的误报率?
DLP 规则和策略的制定与管理(日常的日志、风险和事件的审计与跟踪)是一项繁重的工作,配置的不合理或不准确,会导致较高的误报率,同时也会影响内部用户体验以及公司业务运行。
本文从实践经验出发,围绕如何降低规则误报率,分享一些规则配置的指南/技巧,希望能对相关的安全从业者们提供一些思考与帮助。
01
制定文件识别规则时,词汇的数量不是越多越好,而是词汇的准确性越高越好。因为许多词语是通用的,如果单条识别规则包含了过多的关键词,可能会误识别其他类型的文档。
例如:若要识别特定的财务报告,如果规则中仅包含如“财务”“报告”“数据”这样的通用词汇,虽然这些词汇频繁出现在财务报告中,但同样也会出现在其他类型的文档,如市场分析报告或内部会议纪要。这样的规则可能导致系统错判,从而产生误报。
相反,如果规则包含更准确的词汇组合,如“财务年度”“盈利报表”“资产负债表”等,这些词汇不仅在财务报告中出现频率高,且很少出现在其他类型的文档中。这样的规则将更准确地识别财务报告,减少误报的可能性。
02
尽量使用 "至少命中M项" 这样的条件,而 "至少命中N次" 这样的条件适合作为辅助条件。
例如:要判断一个文档是否为规划类文档,【至少命中“目标、研发项目、建设、关键节点、里程碑、方案、资源”5 项(即这 7 个词中有 5 个出现在一个文档中)】的规则准确率会高于 【至少命中 5 次(可能存在命中了“建设” 5 次的情况)】。
03
在识别规则中可以加入公司名称/简称或者是公司专属名词,以排除非本公司的文件。
例如:可以通过增加“薮猫”“薮猫科技”“青骓 DDR”等公司专属名称,或者有特色的高管人名/花名等,可进一步锁定公司内部文件,缩小识别范围。同时,也可以辅助增加命中的次数来提高识别精准度。
04
可以加入文件后缀作为判断条件。
例如:报表、列表类文件,一般都为 excel 文件。
05
可以适当地对关键词进行拓展与扩充,若靠个人实在想象不出更多常用词语,也可以尝试问问 ChatGPT 。
.png)
06
规则上线后,多查看风险详情日志,分析每个误报的原因,继而完成策略/规则的优化。
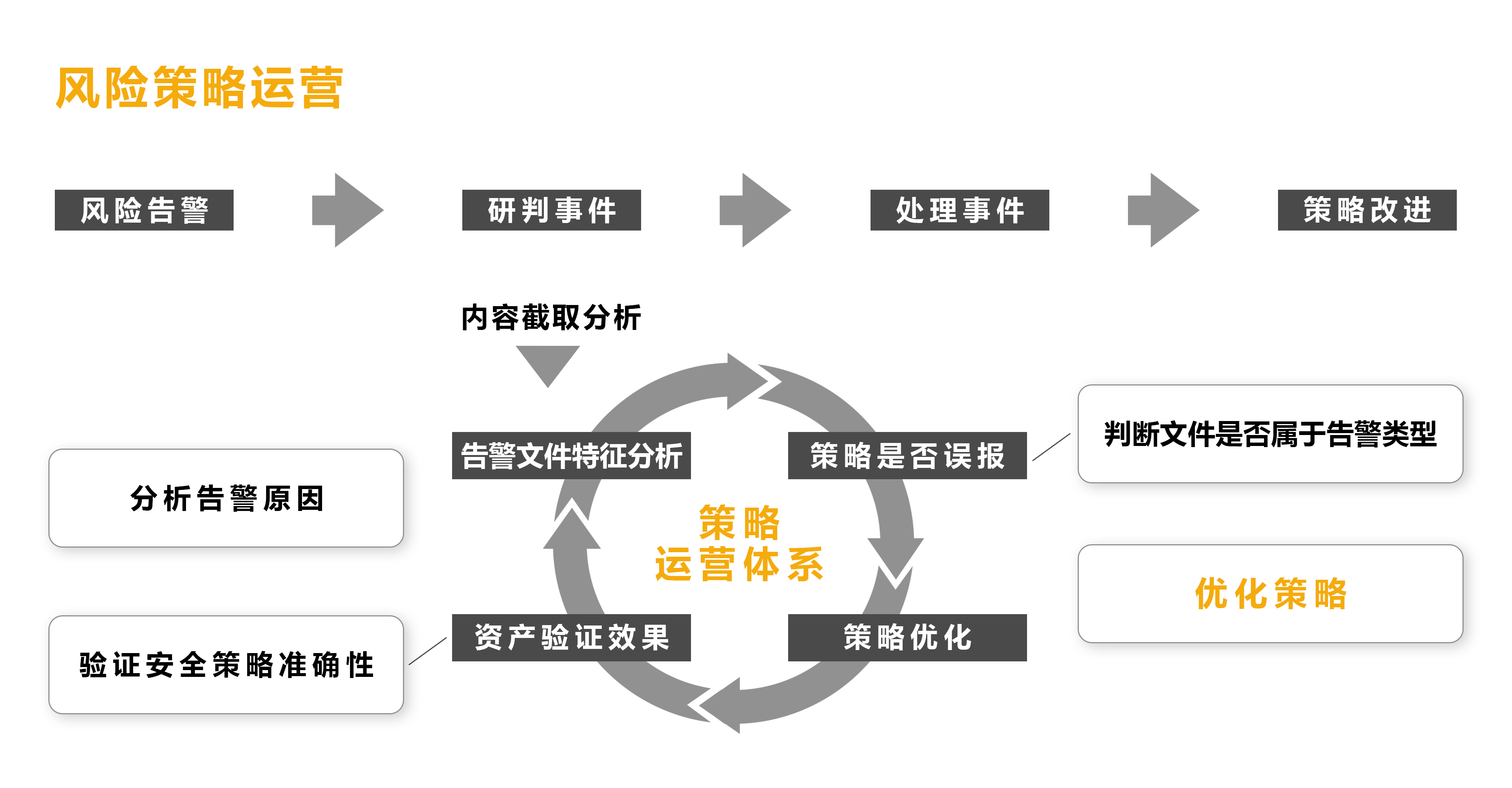
青骓 DDR 提供了更智能、更高效的方式
01
内置丰富成熟的安全规则与策略,一键启用。
凭借薮猫科技团队在安全行业的丰富实践经验,青骓 DDR 在遵循以上原则的基础上,内置各类成熟的安全规则与策略,让安全策略的配置和使用变得简单易行。
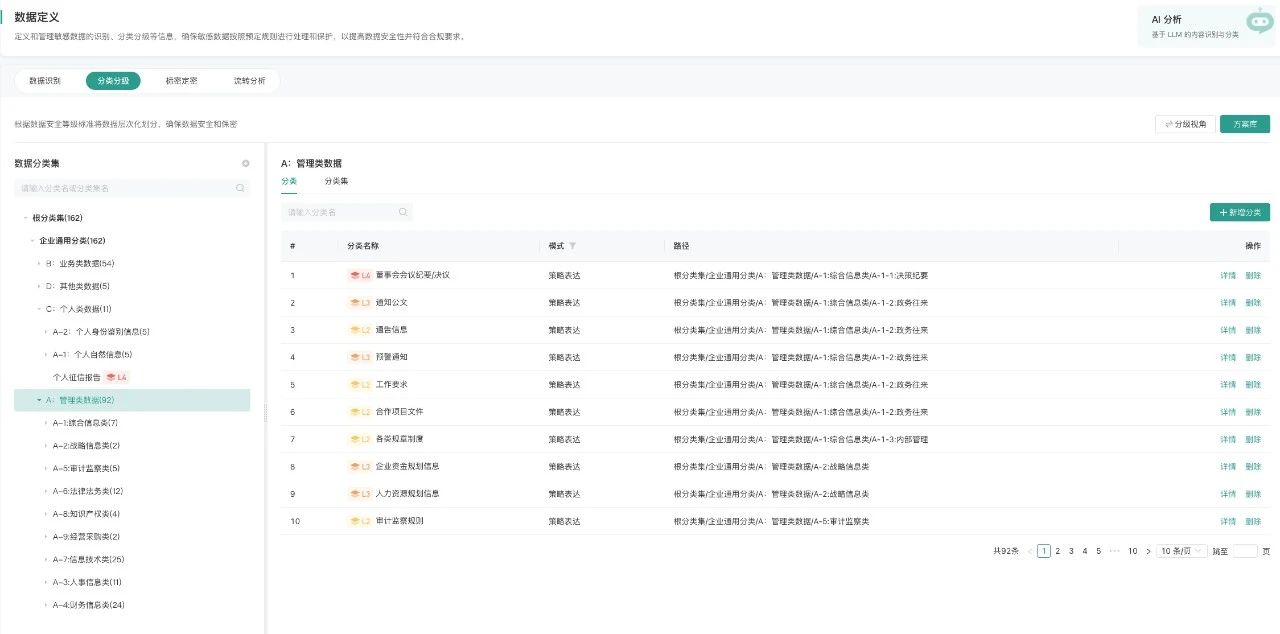
02
主 & 被动数据持续发现,逐渐完善文件识别规则。
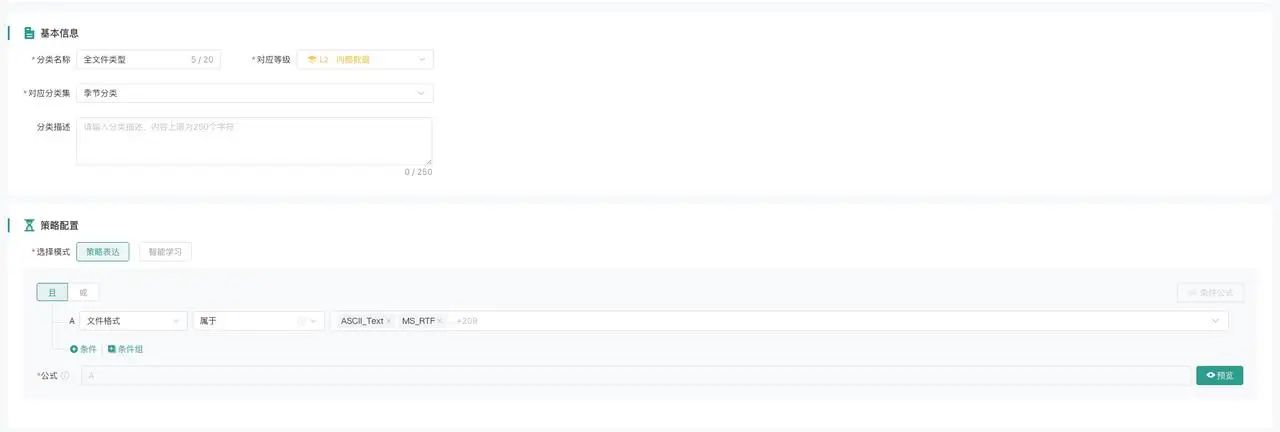
青骓 DDR 通过资产主动发现功能,可以对企业数据文件进行全盘扫描,再通过聚类功能将相似的文件聚合,提取出类似文件的关键词,做成文件内容识别规则。
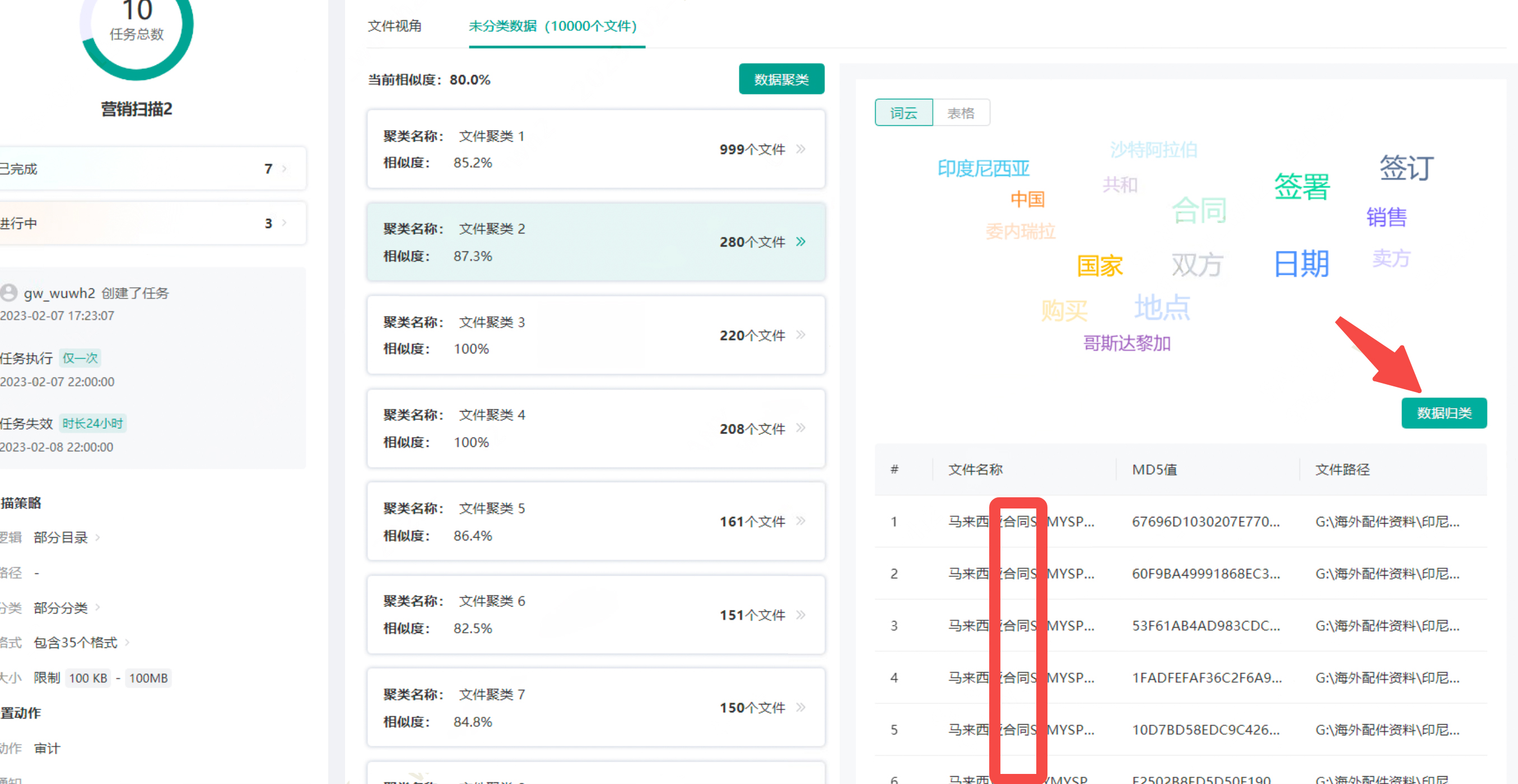
此外,青骓 DDR 还支持将所有办公文件都进行审计,通过每天查看传输的文件名来进一步补充和完善分类集和文件名识别规则。
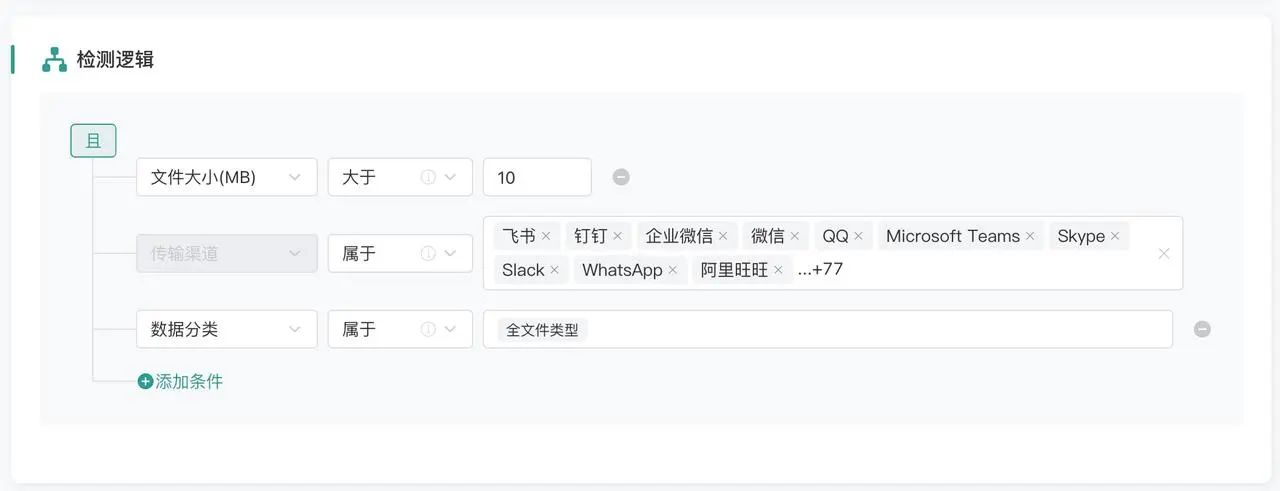
03
AI 技术的深化应用:实现效率的倍增。
青骓 DDR 利用 AI 技术,对数据文件进行智能精准识别,大幅提升安全运营效率。
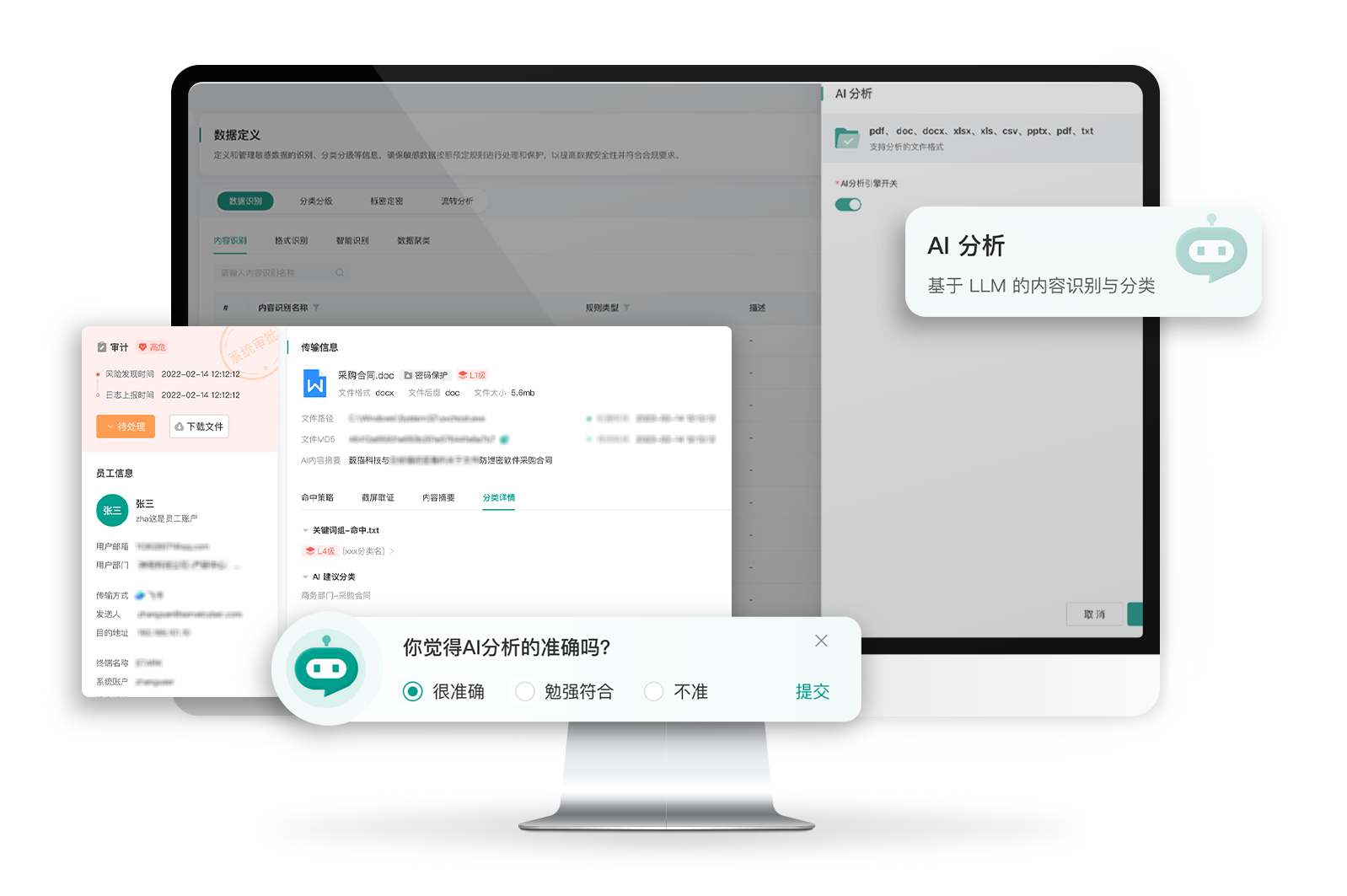
规则和策略的配置是一个需要持续思考和优化的过程,它要求安全团队不断深入理解业务流程和数据分类分级,并全面考虑各种潜在的数据泄露场景。同时,由于数据类型和业务场景的多样性,安全团队需要动态调整和持续优化,以应对环境的不断变化。